-
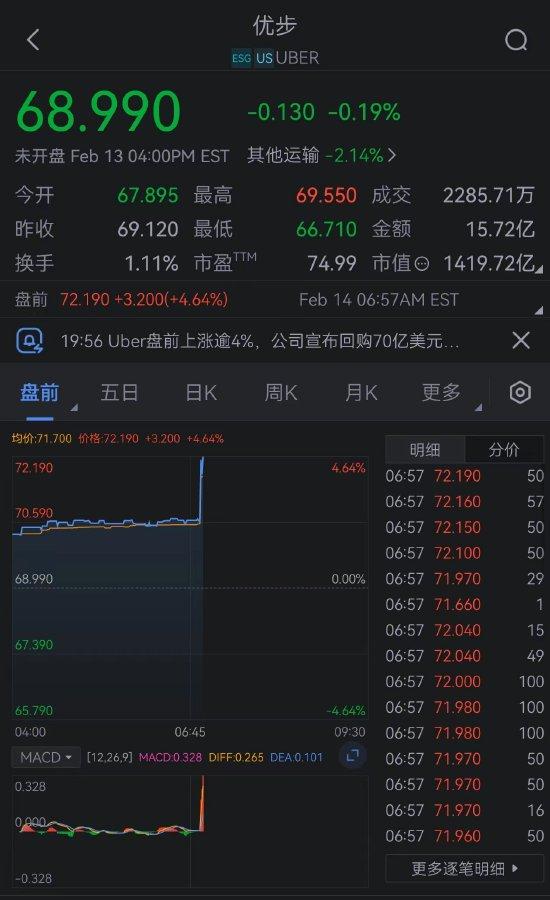
Uber盘前上涨逾4%,公司宣布历史首次回购
科技 | 03-05 | 9119个浏览Uber盘前上涨逾4%,公司宣布回购70亿美元股份。Uber首席财务官表示,这是公司首次授权实施股票回购计划,并称“这是对公司强劲的财务势头投下的信任票”。上周,Uber发布了2023年第四季度财报,连续三个季度实现盈利,同时也首次实现了全年盈利。从而使其成为最新一家提高对股东回...
-

传苹果VisionPro 4或5月登陆中国,大厂应用火速跟进
科技 | 03-05 | 8507个浏览Apple Vision Pro 目前仅在美国推出,但从一开始就有报道称它将很快在国际上推广。《华尔街新闻》快讯报道,供应链预计该产品最早可能于 4 月份在中国发布。它明确表示“最早四月(但不晚于五月)”。目前还没有更多细节,但供应链还声称“工信部的注册程序已接近完成”。消息预计...
-

号称绝对安全的iOS发现木马病毒,你的苹果手机可能已被黑客控制
科技 | 03-05 | 7250个浏览划重点1、网络安全公司Group-IB发现了首款针对iOS系统的木马病毒。2、GoldDigger原本是针对安卓系统开发的,现在的改进版本开始威胁iOS用户。3、苹果似乎已经发现这种病毒的威胁,并采取了封锁措施。腾讯科技讯 2月17日消息,据外媒报道,苹果始终致力于为其操作系统提...
-

力箭二号液体运载火箭计划2025年首飞
科技 | 03-05 | 8297个浏览记者今天从中国科学院获悉,中科宇航与中国科学院微小卫星创新研究院近日举行中国空间站低成本货物运输系统总体方案讨论确认会,明确了由中科宇航力箭二号液体运载火箭发射卫星创新院自主研制的低成本货运飞船产品,将于2025年执行首次飞行任务。同时,首飞还可搭载低轨互联网星座卫星。2023年...
-
Sora爆火48小时:杨立昆揭秘论文,参数量或仅30亿
科技 | 03-05 | 7351个浏览OpenAI新爆款Sora的热度持续发酵,在科技圈的刷屏阵仗都快赶上正月初五迎财神了。智东西2月17日报道,这两天,OpenAI首款文生视频大模型Sora以黑马之姿占据AI领域话题中心,马斯克、杨立昆、贾扬清、Jim Fan、谢赛宁、周鸿祎、李志飞等科技人物纷纷下场评论,一些视频...
-
推倒万亿参数大模型内存墙,万字长文:从第一性原理看神经网络量化
科技 | 03-05 | 7173个浏览【新智元导读】为了应对大模型不断复杂的推理和训练,英伟达、AMD、英特尔、谷歌、微软、Meta、Arm、高通、MatX以及Lemurian Labs,纷纷开始研发全新的硬件解决方案。从32位,到16位,再到8位,量化在加速神经⽹络⽅⾯发挥了巨⼤作⽤。放眼一看,世界把所有的⽬光都聚...
-

【光明论坛】为乡村振兴提供强大的人才队伍支撑
科技 | 03-05 | 5860个浏览近日,2024年中央一号文件公布,文件明确提出“壮大乡村人才队伍”,进一步强调了人才培养对乡村振兴的重要意义,为有力有效推进乡村全面振兴擘画了路线图。乡村振兴,关键在人。人才振兴是乡村振兴的基础,加强乡村人才队伍建设是推进乡村全面振兴的题中应有之义。针对当前农村发展中缺人才的问题...
-

去哪儿:今年春节坐飞机出游的人比返乡的人多,游客覆盖全球1754个城市
科技 | 03-05 | 6609个浏览新浪科技讯 2月17日上午消息,“出游”代替“返乡”成主角。去哪儿数据显示,今年假期中间不仅没有出现出行低谷,从单日出行量看,选择初二(2月11日)坐飞机出游的人比腊月二十九(2月8日)返乡的人还要多。今年春节假期中国游客足迹遍布全球115个国家,覆盖全球1754个城市(除中国大...
-

亿纬锂能成价格战风暴中的幸存者
科技 | 03-04 | 7200个浏览2月5日晚,动力电池二线龙头厂商亿纬锂能发布2023年业绩预告。归属上市公司股东的净利润维持同比正增长,虽然不如龙头厂商宁德时代,但相比孚能科技等全年亏损的二三线电池企业还是相对出色。亿纬锂能在2023年,实现归属于上市公司股东的净利润40.35亿元-42.11亿元,同比增长15...
-

NBA 和 WWE 2K 游戏开发商 Visual Concepts 再次裁员,业界血洗仍在持续
科技 | 03-04 | 4944个浏览IT之家 2 月 8 日消息,位于得克萨斯州奥斯汀的游戏开发商 Visual Concepts 近日再次宣布裁员,这次裁员影响到了旗下多个游戏项目,包括即将于明年春天发售的《WWE 2K24》。具体裁员人数并未公布,但据悉本次裁员涉及《WWE 2K24》《NBA 2K》以及《LE...
-

巴菲特连续四年居首!《福布斯》公布2024年度美国慈善富豪25强
科技 | 03-04 | 7918个浏览《福布斯》今日评出了2024年度美国最慷慨的25位亿万富豪,他们在去年向一系列事业捐赠了数百亿美元,从医疗和科学研究到环境可持续性,再到为低收入美国人群提供法律服务等。数据显示,截至2023年12月30日,这25位慈善家的累计捐赠总额升至近2110亿美元,较去年增长了约7%。过去...
-

奥特曼警告:“社会失调”可能放大人工智能风险
科技 | 03-04 | 6021个浏览OpenAI首席执行官萨姆·奥特曼周二表示,让他在人工智能方面夜不能寐的危险是“非常微妙的社会失调”,这可能会使系统造成严重破坏。在迪拜举行的世界政府峰会上,奥特曼通过视频电话发表讲话,再次呼吁成立一个像国际原子能机构这样的机构来监管人工智能,因为人工智能的发展速度可能比世界预期...
-

华硕发布a豆14 Air轻薄本:女性用户的“智能闺蜜” 首发价5299元
科技 | 03-04 | 5841个浏览新浪数码讯 2月19日上午消息,PC制造商华硕召开a豆新品发布会,正式推出专为女性用户打造的AI超轻薄本a豆14 Air,主打颜值和AI,助力女性用户展现自信、勇敢出击。轻薄外观,鲜明配色华硕认为,时尚是女性生活态度和个性的表达。而本次推出的a豆14 Air拥有瑰蜜粉金、鼠尾草青...
-

任继周院士新作《中国农业伦理学》发布
科技 | 03-04 | 5547个浏览近日,任继周院士《中国农业伦理学》新书发布仪式暨《任继周著作集》电子书赠送仪式在兰州大学举行。这部由任继周院士主编的《中国农业伦理学》,为助力我国生态文明建设和农业可持续发展拓展清晰思路,为解决当代农业农村农民发展问题开辟新的途径。近日,任继周院士《中国农业伦理学》新书发布仪式暨...
-

重磅!OpenAI首个视频生成模型发布,1分钟流畅高清,效果炸裂
科技 | 03-04 | 6395个浏览据OpenAI官网,OpenAI首个视频生成模型Sora发布,完美继承DALL·E 3的画质和遵循指令能力,能生成长达1分钟的高清视频。AI想象中的龙年春节,红旗招展人山人海。有紧跟舞龙队伍抬头好奇官网的儿童,还有不少人掏出手机边跟边拍,海量人物角色各有各的行为。一位时髦女士漫步...
-

盘点|OpenAI首个视频模型发布,竞争者有谁、何时可供使用?
科技 | 03-04 | 6453个浏览人工智能在去年给人类带来巨大冲击,不少声音指出在创意等方面人类尚无法被其取代。这一想法再次遭到挑战。当地时间2月15日,人工智能巨头,ChatGPT母公司OpenAI宣布,正在研发“文生视频”模型Sora,可创建长达60秒的视频,其中包含高度详细的场景、复杂的摄像机运动以及充满活...
-

淘天集团第三财季营收1290.7亿元 同比增长2%
科技 | 03-04 | 7753个浏览新浪科技讯 北京时间2月7日晚间消息,阿里巴巴(NYSE: BABA;HKEX: 9988)今日发布了截至2023年12月31日的2024财年第三财季财报:营收为2603.48亿元,同比增长5%。净利润为107.17亿元,同比下滑77%;不按美国通用会计准则,净利润为479.51...
-

根据对土星卫星土卫一轨道的近距离测量,科学家发现,其冰冷的外壳下似乎有一片广阔的全球性海洋。如果其他“冰世界”也有类似的海洋,可能会增加宜居行星的数量。2月7日,相关研究成果发表于《自然》。根据对土星卫星土卫一轨道的近距离测量,科学家发现,其冰冷的外壳下似乎有一片广阔的全球性海洋...
-

带个保温杯上讲台讲化学,赵东元院士说做科研最重要是“爱”
科技 | 03-04 | 5822个浏览“如果我把保温杯里的化学物质倒入大海,过一周后再把海水捞上来,还能找到保温杯里原有的化学物质吗?”12月28日,在复旦大学相辉堂举行的第五期浦江科学讲坛上,复旦大学化学与材料学院院长、复旦大学相辉研究院首任院长赵东元以“‘孔’中看世界——无尽的科学前沿”为题作报告。他带着一个保温...
-

百年几何事 人生一卷诗——苏步青的诗情与诗思
科技 | 03-04 | 5861个浏览【科学家的诗词情缘】开栏的话翻开现当代诗词集,不少科学家的身姿活跃其间。这些科学家,纵横于科学的世界,也驰骋于诗词的田野。他们接续先哲余韵,创作出一首首饱含深情的古典诗词佳作。这些诗篇,是现代科学与传统文化的碰撞,也是时代脉动与个人情怀的交融。本版今起开设《科学家的诗词情缘》栏目...
-

消失的摩托车返乡大军
科技 | 03-04 | 9436个浏览每逢过年,春运无疑是最被人关注的话题。成千上百万的异地打工人,在忙碌了一年之后,期待着能够在过年期间回到家乡和家人团聚。而在遭遇冻雨和暴雪等极端天气导致高铁、飞机大量延误,高速大面积拥堵的情况下,今年的春运,无疑又是相当艰难的一年。绿皮火车、高铁动车乃至飞机甚至自驾,春运返乡的方...
-

大尺寸液晶面板迎涨价 厂商按需生产主导市场
科技 | 03-04 | 6949个浏览再度迎来涨价。2月6日上午,TrendForce集邦咨询发布的最新面板报价显示,2月上旬65吋电视面板均价为164美元,较1月下旬上涨1美元;55吋电视面板均价为123美元,价格上涨1美元。TrendForce集邦咨询分析师范博毓在接受《证券日报》记者采访时表示:“预期2月份65...
-

黄彦熙:认真对待每一位患者
科技 | 03-04 | 5272个浏览今年7月,四川大学学生黄彦熙在2023年港澳台大学生暑期实习活动中体验采茶。四川省科学技术协会供图在成都的这段学习生涯,这位台湾青年有机会接触更多的人和事,也认识了更多来自全国各地的同学和朋友。将来,他希望在大陆开启自己的职业生涯。——————————对医学生黄彦熙来说,10月2...
-

中国科学院2024跨年科学演讲传播量超2.58亿人次
科技 | 03-04 | 9178个浏览2023年12月31日,中国科学院举办了以“复兴路上的科学力量”为主题的2024跨年科学演讲活动,并联合上海广播电视台“日出东方?科技追光”跨年融媒直播,组成了超30小时的超级跨年直播。截至1月2日,全网累计传播量超2.58亿人次。2023年12月31日,中国科学院举办了以“复兴...
-

大众推出 ID.7 Tourer 旅行版电动汽车,续航最高达 685 公里
科技 | 03-04 | 8505个浏览IT之家 2 月 20 日消息,大众汽车集团今天宣布在其 ID 系列纯电动汽车阵容中新增一款车型 ——ID.7 Tourer。这是一款基于 ID.7 轿车打造的旅行版车型,拥有更大的载货空间和更长的续航里程,专为欧洲市场打造,预售即将开启。根据大众汽车集团的新闻稿,ID.7 To...
-

中学生对话企业科技工作者 感受科学魅力
科技 | 03-04 | 9417个浏览近日,“美一次·科技筑梦”公益活动在美的全球创新中心举行。来自华东师范大学附属顺德美的学校以及德胜学校的40多名初中生与3名美的科技工作者对话,共同感受科学的魅力。近日,“美一次·科技筑梦”公益活动在美的全球创新中心举行。来自华东师范大学附属顺德美的学校以及德胜学校的40多名初中...
-

关于Apple Vision Pro的一些启发
科技 | 03-03 | 9202个浏览市面上对于Apple Vision Pro的解读有很多,但少有涉及AR/VR产品根本性问题的了解和洞察。关于Vision Pro理想应用是“空间显示“?Elon Musk评价AVP,"我不明白为什么要将电视机挂在鼻子上“,其实这句评论没有贬低AR/VR,甚至还高估了。因为使用VR...
-

荣耀小米超旗舰双双入网 卫星、影像大战一触即发
科技 | 03-03 | 4956个浏览荣耀小米超旗舰双双入网 卫星、影像大战一触即发【手机中国新闻】2月15日,知名数码博主数码闲聊站爆料,小米14 Ultra和荣耀Magic6 RSR都入网了,两台5G卫星移动终端,新一轮影像旗舰大战。从入网信息来看,两款产品设备名称都是“卫星移动终端”,荣耀的产地在深圳,而小米的...
-

智谱接连被卖掉的股份,又被老股东买走了
科技 | 03-03 | 6560个浏览近日,国内头部大模型初创公司智谱AI被早期投资方中科创星接连减持之事引发业内关注。1月22日,界面新闻从知情人士处独家获悉,中科创星所减持的股份已被包括君联资本和Boss直聘等在内的老股东接盘。另外,智谱还将引入新的投资者。作为国内头部基座大模型公司,智谱AI在过去一年中备受关注...
-

苹果又摊上大事!欧盟要开出近40亿元天价罚单
科技 | 03-03 | 4581个浏览快科技2月20日消息,据英国《金融时报》18日报道,欧盟委员会预计将对美国苹果公司处以约5亿欧元、约合38.8亿元人民币的罚款。罚款理由是该公司在音乐流媒体服务方面存在妨碍市场竞争的行为。欧盟委员会下属的反垄断监管机构称,苹果违反了欧盟法律,“阻止其竞争对手通知iPhone用户,...








































